
Index Coverage is a report in Google Search Console that shows the crawling and indexing status of all URLs that Google has discovered for your website.
It helps you track your website’s indexing status and keeps you informed about technical issues preventing your pages from being crawled and indexed correctly.
Checking the Index Coverage report regularly will help you spot and understand issues and learn how to address them.
In this article, I will describe:
- What the Index Coverage report is,
- When and how you should use it,
- The statuses shown in the report, including types of issues, what they mean, and how to fix them.
When was the Index Coverage report introduced?
Google introduced the Index Coverage report in January 2018 when it started releasing a revamped version of the Search Console to all users.
Apart from Index Coverage, the improved Search Console contained other valuable reports:
- The Search performance report,
- Reports on Search enhancements: AMP status and Job posting pages.
Google said the redesign of the Google Search Console was motivated by feedback from users. The goal was to:
- Add more actionable insights,
- Support the cooperation of different teams that use the tool,
- Offer quicker feedback loops between Google and users’ sites.
The 2021 Index Coverage report update
In January 2021, Google improved the Index Coverage report to make the reported indexing issues more accurate and clear to users.
The changes to the report consisted of:
- Removing the generic “crawl anomaly” issue type,
- Making pages that were submitted but blocked by robots.txt and got indexed reported as “indexed but blocked” (in warnings) instead of “submitted but blocked” (error),
- Adding an issue called “indexed without content” (to warnings),
- Making the reporting of the soft 404 issues more accurate.
Google’s indexing pipeline
Before digging into the report’s specifics, let’s discuss the steps Google needs to take to index and, eventually rank web pages.
For a page to be ranked and shown to users, it needs to be discovered, crawled, and indexed.
Discovery
Google needs to first discover a page to be able to crawl it.
Discovery can happen in a few ways.
The most common ones are for Googlebot to follow internal or external linking to a page or find it through an XML sitemap, which is a file that lists and organizes the URLs on your domain.
Crawling
Crawling consists of search engines exploring web pages and analyzing their content.
An essential aspect of crawling is the crawl budget, which is the amount of time and resources that search engines can and want to spend on crawling your site. Search engines have limited crawling capabilities and can only crawl a portion of pages on a website.
Indexing
During indexing, Google evaluates the pages and adds them to the index – a database of all web pages that Google can use to generate search results. This stage also consists of rendering, which helps Google see the pages’ layout and content. The information Google gathers about a page helps it decide how to show it in search results.
But, just because Google can find and crawl your page, doesn’t mean it will be indexed.
Getting indexed by Google has been getting more complicated. This is mainly because the web is growing, and websites are becoming heavier.
But here is the crucial indexing aspect to remember: you shouldn’t have all of your pages indexed.
Instead, ensure the index only contains your pages with high-quality content valuable to users. Some pages can have low-quality or duplicate content and, if search engines see them, it may negatively affect how they view your site as a whole.
That’s why it’s vital to create an indexing strategy and decide which pages should and shouldn’t be indexed. By preparing an indexing strategy, you can optimize your crawl budget, follow a clear indexing goal and fix any issues accordingly.
Ranking
Pages that are indexed can be ranked and appear in search results for relevant queries.
Google decides how to rank pages based on numerous ranking factors, such as the amount and quality of links, page speed, mobile-friendliness, content relevance, and many others.
How to use the Index Coverage report?
To get to the Index Coverage report, log in to your Google Search Console account. Then, in the menu on the left, select “Coverage” in the Index section:
You will then see the report. By ticking each or all of the statuses, you can choose what you want to visualize on the chart:
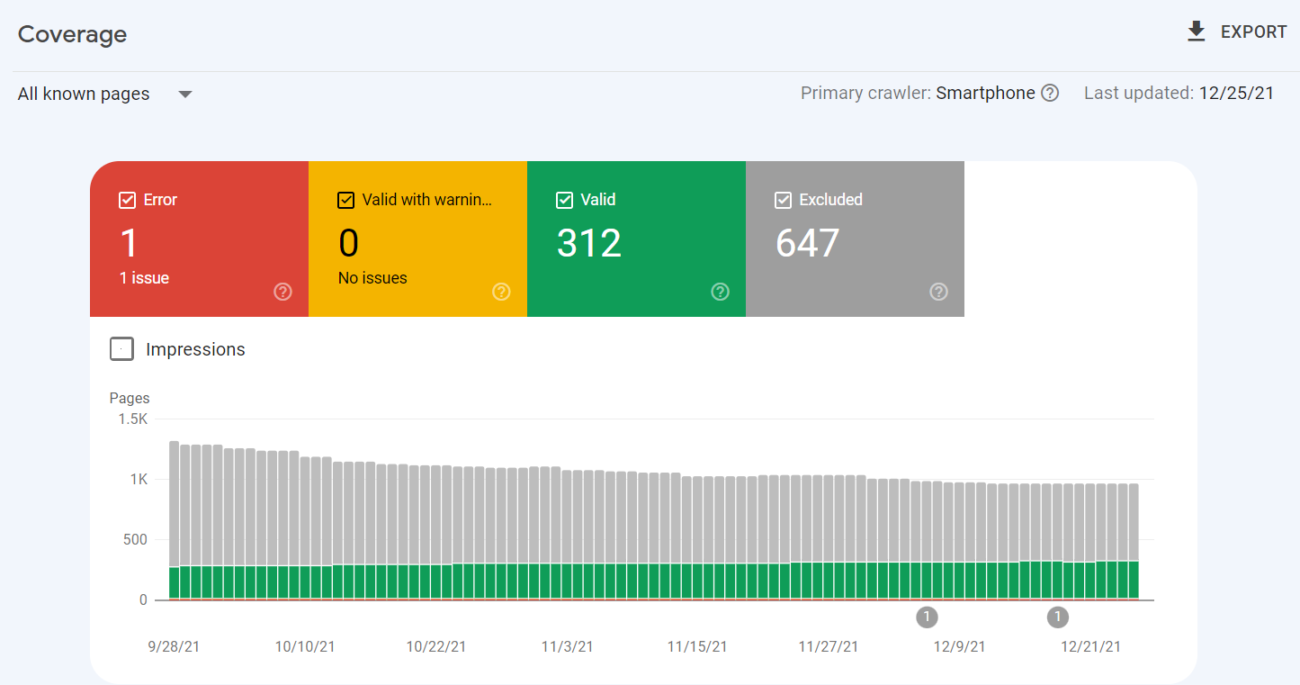
The report will show URLs that respond with the following four statuses, connected with different issues Google encountered on specific pages:
- Error – critical issues in crawling or indexing.
- Valid with warnings – URLs that are indexed but contain some non-critical errors.
- Valid – URLs that have been correctly indexed.
- Excluded – pages that haven’t been indexed due to issues – this is the most important section to focus on.
“All submitted pages” vs “All known pages”
In the upper left corner, you can select whether you want to view “All known pages”, which is the default option, showing URLs that Google discovered by any means, or “All submitted pages”, including only URLs submitted in a sitemap.
You should find a stark difference between the status of “All submitted pages” and “All known pages” – “All known pages” normally contain more URLs and more of them are reported as Excluded. That’s because sitemaps should only contain indexable URLs while most websites contain many pages that shouldn’t be indexed. One example is URLs with tracking parameters on eCommerce websites. Search engine bots like Googlebot may find those pages by various means, but they should not find them in your sitemap.
So always be mindful when opening the Index Coverage report and make sure you’re looking at the data you’re interested in.
Inspecting the URL statuses
To see the details on the issues found for each of the statuses, look below the chart:
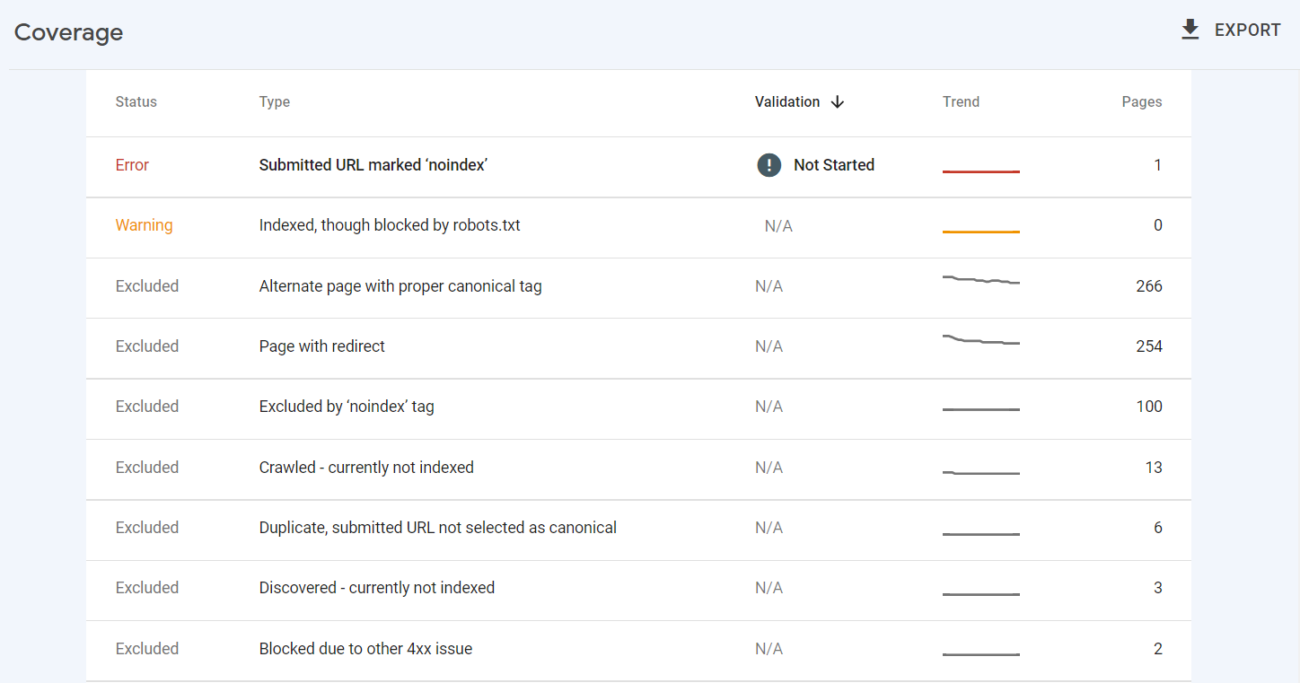
This section displays the status, specific type of issue, and the number of affected pages.
You can also see the validation status – after fixing an issue, you can inform Google that it has been addressed and ask to validate the fix.
This is possible at the top of the report after clicking on the issue:
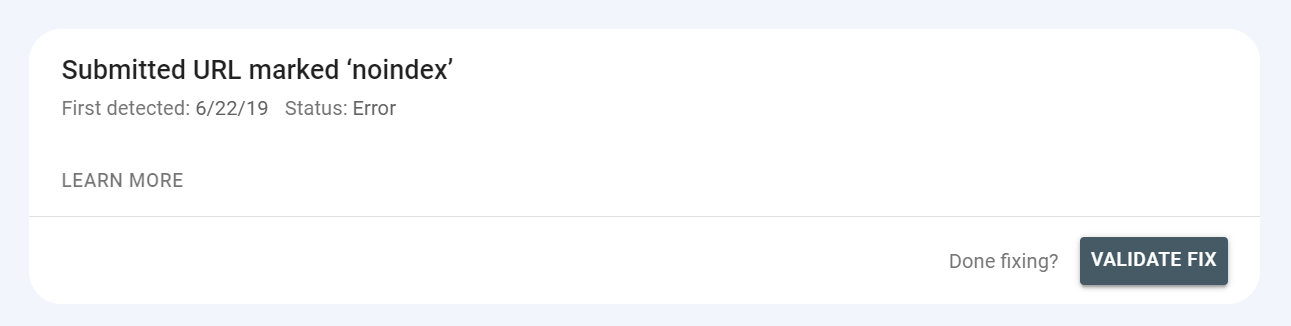
The validation status can appear as “fixed”. But it can also show “failed” or “not started” – you should prioritize fixing issues that respond with these statuses.
You can also see the trend for each status – whether the number of URLs has been rising, dropping, or staying on the same level.
After clicking on one of the types, you will see which URLs respond with this issue. In addition, you can check when each URL was last crawled – however, this information is not always up-to-date due to possible delays in Google’s reporting.
There is also a chart showing the dates and how the issue changed over time.
Here are some important considerations you should be aware of when using the report:
- Always check if you’re looking at all submitted pages or all known pages. The difference between the status of the pages in your sitemap vs all pages that Google discovered can be very stark.
- The report may show changes with a delay, so whenever you release new content, give it at least a few days to get crawled and indexed.
- Google will send you email notifications about any particularly pressing issues encountered on your site.
- Your aim should be to index the canonical versions of the pages you want users and bots to find.
- As your website grows and you create more content, expect the number of indexed pages in the report to increase.
How often should you check the report?
You should check the Index Coverage report regularly to catch any mistakes in crawling and indexing your pages. Generally, try to check the report at least once a month.
But, if you make any significant changes to your site, like adjusting the layout, URL structure, or conducting a site migration, monitor the results more often to spot any negative impact. Then, I recommend visiting the report at least once a week and paying particular attention to the Excluded status.
URL Inspection tool
Before diving into the specifics of each status in the Index Coverage report, I want to mention one other tool in the Search Console that will give you valuable insight into your crawled or indexed pages.
URL inspection tool provides details about Google’s indexed page version.
You can find it in Google Search Console in a search bar at the top of the page.
Simply paste a URL that you want to inspect – you will then see the following data:
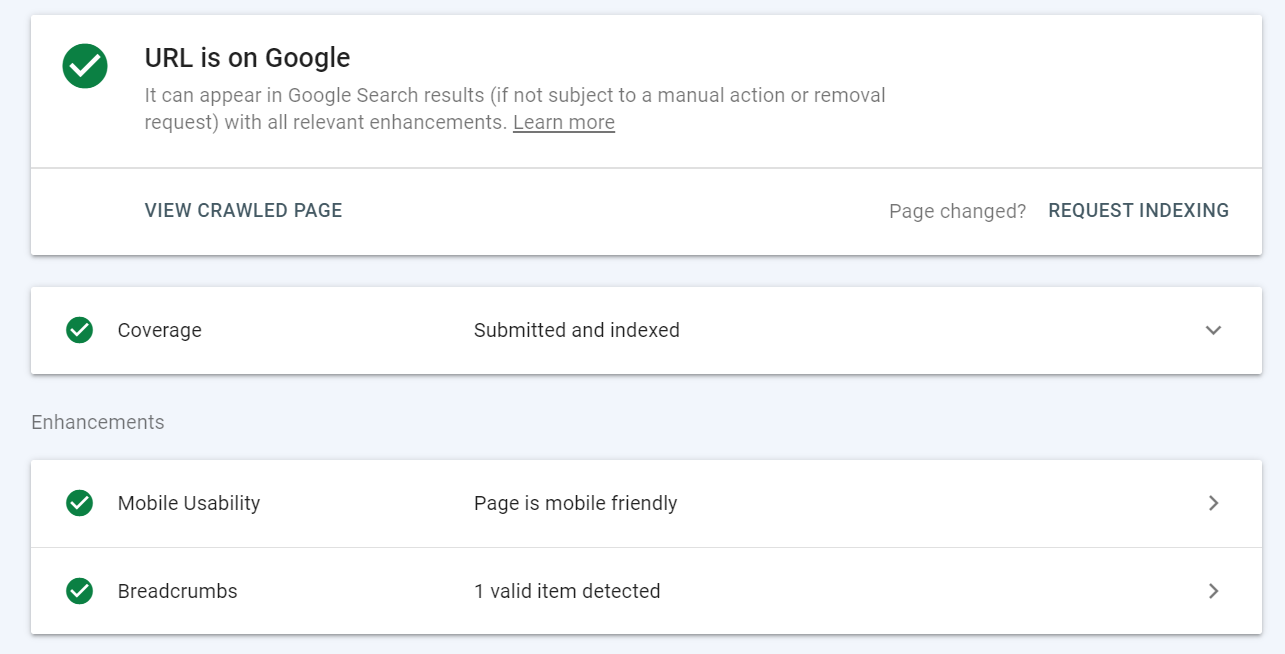
You can use the URL inspection tool to:
- Check the index status of a URL and, in case of issues, see what they are and troubleshoot them,
- Learn if a URL is indexable,
- View the rendered version of a URL,
- Request indexing of a URL – e.g., if a page has changed,
- View loaded resources, such as JavaScript,
- See what enhancements a URL is eligible for – e.g., based on the implementation of structured data and whether the page is mobile-friendly.
If you encounter any issues in the Index Coverage report, use the URL inspection tool to verify them and test the URLs to better understand what should be fixed.
Statuses in Index Coverage report and types of issues
It’s time to look at each of the four statuses in the report and:
- Discuss the specific issue types that they can show,
- What causes these issues, and
- How you should address them.
Error
The error section contains URLs that have not been indexed due to errors that Google encountered.
Whenever you see an issue containing “Submitted,” it concerns URLs that have been submitted for indexing, which is generally done through a sitemap, and that’s how Google discovered them. Ensure your sitemap only contains URLs that you want to be indexed.
Server error (5xx)
As indicated by the name, it refers to server errors with 5xx status codes, such as 502 Bad Gateway or 503 Service Unavailable.
You should monitor this section regularly, as Googlebot will have trouble indexing pages with server errors. You may need to contact your server administrator to fix these errors or check if they are caused by any recent upgrades or changes on your site.
Redirect error
Redirects transfer search engine bots and users from an old URL to a new one. They are usually implemented when old URLs change or their content doesn’t exist anymore.
Redirect errors point to the following problems:
- Redirect chain (which occurs when there are multiple redirects between URLs) is too long,
- Redirect loop – URLs redirect to each other,
- Redirect URL that exceeded the maximum URL length,
- A wrong or empty URL was found in the redirect chain.
Check and fix the redirects for each affected URL
Submitted URL blocked by robots.txt
These URLs were submitted in a sitemap but are blocked in robots.txt. Robots.txt is a file containing instructions on how robots should crawl your site. If this URL should be indexed, Google needs to crawl it first, so head to your robots.txt file and adjust the directives.
Submitted URL marked ‘noindex’
Similar to the previous error, these pages were submitted for indexing but are blocked by a noindex tag or header in the HTTP response. ‘Noindex’ prevents a page from getting indexed – if the affected URLs should be indexed, remove the noindex directive.
Submitted URL seems to be a Soft 404
A soft 404 error means a page returns a 200 OK status, but its contents make it look like an error, e.g., because it’s empty or contains thin content. Review pages with this error and check if there is a way to change their content or redirect them.
The 401 Unauthorized status code means that a request cannot be completed because it’s necessary to log in with a valid user ID and password. Googlebot cannot index pages hidden behind logins – in this case, either remove the authorization requirement or verify Googlebot so it can access the pages.
Submitted URL not found (404)
404 error pages indicate that the requested page could not be found because it changed or was deleted. Error pages exist on every website and, generally, a few of them won’t harm your site. But, whenever a user encounters an error page, it may lead to a negative experience.
If you see this issue in the report, go through the affected URLs and check if you can fix the errors. For example, you could set up 301 redirects to working pages. Also, make sure that your sitemap doesn’t contain any URLs that return any HTTP status code other than 200 OK.
Submitted URL returned 403
The 403 Forbidden status code means the server understands the request but refuses to authorize it. You can either grant access to anonymous visitors so Googlebot can access the URL or, if this is not possible, remove the URL from sitemaps.
Submitted URL blocked due to other 4xx issue
Your URLs may not be indexed due to 4xx issues not specified in other error types. 4xx errors generally refer to problems caused by the client.
You can learn more about what is causing each problem by using the URL inspection tool. If you cannot resolve the error, remove the URL from your sitemap.
Valid with warnings
URLs that are valid with warnings have been indexed but may require your attention.
Indexed, though blocked by robots.txt
A page has been indexed, but directives in the robots.txt file block it. Typically, these pages wouldn’t be indexed, but it’s likely Google found links pointing to them and considered them important.
Check the affected pages – if they should be indexed, update your robots.txt file to give Google access to them. If these pages shouldn’t be indexed, look for any links pointing to them. If you want the URLs to be crawled but not indexed, implement the noindex directives.
Page indexed without content
These URLs are indexed, but Google was unable to read their content.
Common causes of this issue include:
- Cloaking – showing different content to users and search engines,
- The page is empty,
- Google cannot render the page,
- The page is in a format that Google is unable to index.
Visit these pages yourself and check if the content is visible. Also, go to the URL inspection tool to learn how Googlebot sees it. Then, after fixing the issue or not seeing any problems, you can request that Google reindexes it.
Valid
This status shows URLs that are correctly indexed. However, it’s still good to monitor this report section to see if any URLs shouldn’t be indexed.
Submitted and indexed
These are URLs that are correctly indexed and submitted through a sitemap.
Indexed, not submitted in sitemap
In this situation, a URL has been indexed even though it’s not included in the sitemap.
You should check how Google is getting to this URL. You can find this information in the URL inspection tool.
URLs in this section often include the site’s pagination, which is correct because pagination should not be submitted in sitemaps. Review the URLs and check whether they should be added to the sitemap.
Excluded
These are pages that haven’t been indexed. As you may notice, many issues here are caused by aspects similar to ones in previous sections. The main difference is that Google does not think that excluding the following URLs is caused by an error.
You may find that many URLs in this section have been excluded for the right reasons. But it’s important to regularly check which URLs are not indexed and why to ensure your critical URLs are not kept out of the index.
Excluded by ‘noindex’ tag
A page was not submitted for indexing, but Googlebot found it and could not index it because of a noindex tag. Go through these URLs to ensure the right ones are blocked from the index. If any of the URLs should be indexed, remove the tag.
Blocked by page removal tool
These URLs have been blocked from Google using Google’s Removals tool. However, this method works only temporarily, and, typically after 90 days, Google may show them in search results again. If you want to block a page permanently, you can remove or redirect it or use a noindex tag.
Blocked by robots.txt
The URLs have been blocked in the robots.txt file but not submitted for indexing. You should go through these URLs and check if you intended to block them.
Remember that using robots.txt directives is not a bulletproof way to prevent indexing pages. Google may still index a page without visiting it, e.g., if other pages link to it. To keep a page out of Google’s index, use another method, such as password protection or noindex tag.
In this case, Google received a 401 response code and was not authorized to access the URLs.
This tends to occur on staging environments or other password-protected pages.
If these URLs shouldn’t be indexed, this status is fine. However, to keep these URLs out of Google’s reach, ensure your staging environment cannot be found by Google. For example, remove any existing internal or external links pointing to it.
Crawled – currently not indexed
Googlebot has crawled a URL but is waiting to decide whether it should be indexed.
There could be many reasons for this. For instance, there may be no issue, and Google will index this URL soon. But, frequently, Google will wait to index a page if its content is not quality or looks similar to many other pages on the site. Google then puts it in the queue with a lower priority and focuses on indexing more valuable pages.
Discovered – currently not indexed
This means that Google has found a URL – for example, in a sitemap – but hasn’t crawled it yet.
Keep in mind that in some cases, it could simply mean that Google will crawl it soon. This issue can also be connected with crawl budget problems – Google may view your website as low quality because it lacks performance or contains thin content.
Possibly, Google has not found any links pointing to this URL or encountered pages with stronger link signals that it will crawl first. If there are a lot of better quality or more current pages, Google may skip crawling this URL for months or even never crawl it at all.
Alternate page with proper canonical tag
This URL is a duplicate of a canonical page marked by the correct tag, and it points to the canonical page. Canonical tags are used to specify a URL that represents the primary version of a page. It’s a way of preventing duplicate content issues when many identical or similar pages exist.
In this situation, you don’t need to make any changes.
Duplicate without user-selected canonical
There are duplicates for this page, and no canonical version is specified. It means that Google doesn’t view the specified URLs as canonical.
You can use the URL inspection tool to learn which URL Google chose as canonical. It’s best to choose the canonical version yourself and mark it up accordingly in your URLs using the rel=”canonical” tag.
Duplicate, Google chose different canonical than user
You chose a canonical page, but Google selected a different page as canonical.
The page you want to have as canonical may not be as strongly linked internally as a non-canonical page, which Google may then choose as the canonical version.
One way to address this issue is to consolidate your duplicate URLs.
Not found (404)
These are 404 error pages that were not submitted in a sitemap, but Google still found them.
Google could have discovered them through links or because they existed before and were later deleted.
If it was your intention for this page not to be found, no action is required. Another option is to use a 301 redirect to move the 404 to a working page.
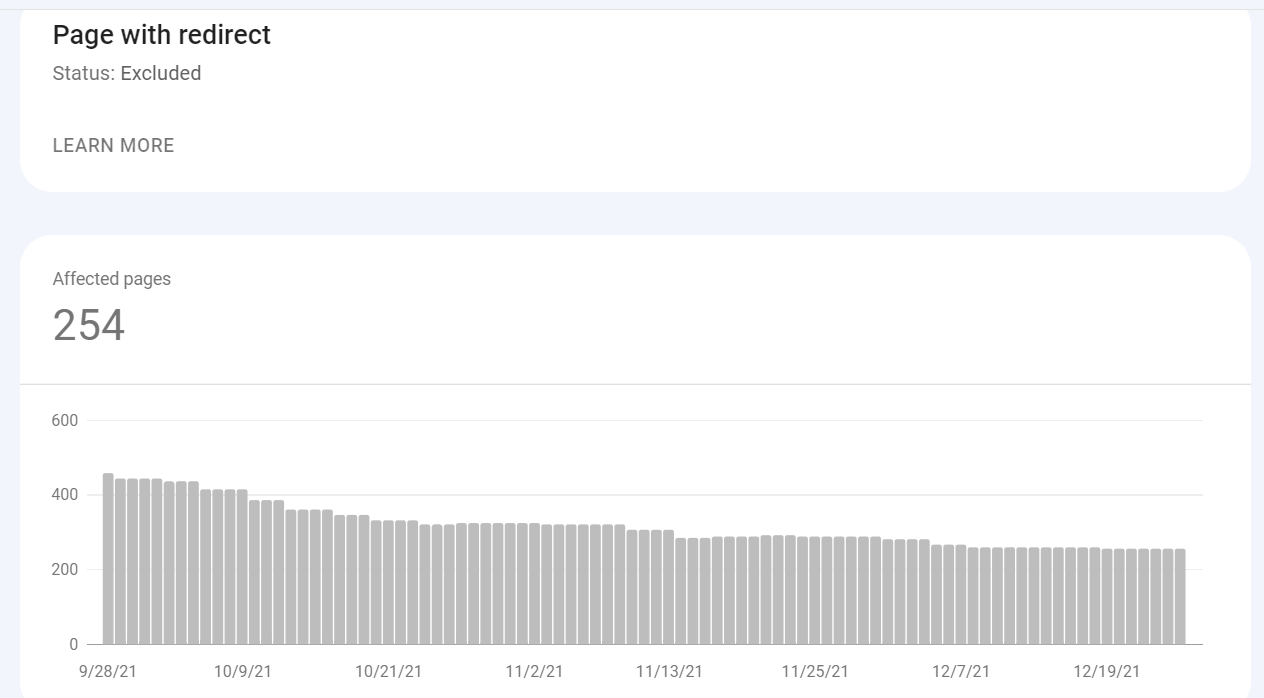
Page with redirect
These pages are redirecting, so they haven’t been indexed. Pages here would generally not require your attention.
For permanently redirecting a page, be sure you implemented a 301 redirect to the closest alternative page. Redirecting 404 pages to the homepage can result in Google treating them as soft 404s.
Soft 404
As mentioned, these URLs resemble error pages but don’t return 404 status codes. For instance, they may be custom 404 pages containing user-friendly content directing to other pages, but returning a 200 OK HTTP code.
To fix soft 404 errors, you can:
- Add or improve the content on these URLs,
- 301 redirect them to the closest matching alternatives, or
- Configure your server to return proper 404 or 410 codes.
Duplicate, submitted URL not selected as canonical
This includes URLs submitted in a sitemap but without canonical versions specified.
Google considers these URLs duplicates of other URLs and has decided to canonicalize these URLs with Google-selected canonical URLs. You should add canonical URLs pointing to the preferred URL versions.
Blocked due to access forbidden (403)
Google couldn’t access these URLs and received a 403 Forbidden error code. If Google shouldn’t access these URLs, it’s better to use a noindex tag.
Blocked due to other 4xx issue
These URLs respond with other 4xx status codes – check these pages to learn what the error is. Then, either fix it according to the specific code that appears or leave the pages as they are.
Conclusion
The Index Coverage report shows a detailed overview of your crawling and indexing issues and points to how they should be addressed, making it a vital source of SEO data.
Your website’s crawling and indexing status is not straightforward – not all of your pages should be crawled or indexed. Ensuring such pages are not accessible to search engine bots is as crucial as having your most valuable pages indexed correctly.
The report reflects the fact that your indexing status is not either black or white. It highlights the range of states that your URLs might be in, showing both serious errors and minor issues that don’t always require action.
Ultimately, you should regularly browse Google’s Index Coverage report and intervene when it doesn’t align with your indexing strategy.